In the last post of the series I promised that we will tackle reimports next. I got almost no feedback about my importer series so I thought must have bored my readership to death. However, I recently got a message asking me whether I am going to continue the series. So, today, as promised, we will enhance our importer to allow updating existing data.
If we run the importer twice in its current state, we get the imported nodes duplicated. Simply clearing the model before an import and recreating it during an import would avoid this problem, but would break any existing references to the previously imported nodes, and this is usually not ideal.
Thus, we are left with trying to find existing nodes in the model and updating them. To be able to do that, we need to know whether a node matches an existing one. To do that, each such node has to carry a domain-specific unique identifier.
Note that not every node has to have an identifier, only nodes that may be referenced from outside the import. The identifiers don’t have to be unique globally, usually uniqueness within a single concept (or item type) is enough.
Previously we have modified our importer to add all nodes to a temporary model first, and add them to the original model in a separate step. We did this originally to avoid leaving the model in incosistent state on failure, but this two-phase approach will also help us with our today’s task.
We will modify the second step to “synchronize” or “merge” the temporary model into the target model, rather than blindly add nodes.
The merge algorithm is an area that may become quite complicated depending on what kinds of changes you want to handle between reimports. In our simple case it is enough to look through the model for an existing node and update it if it exists, or create a new one:
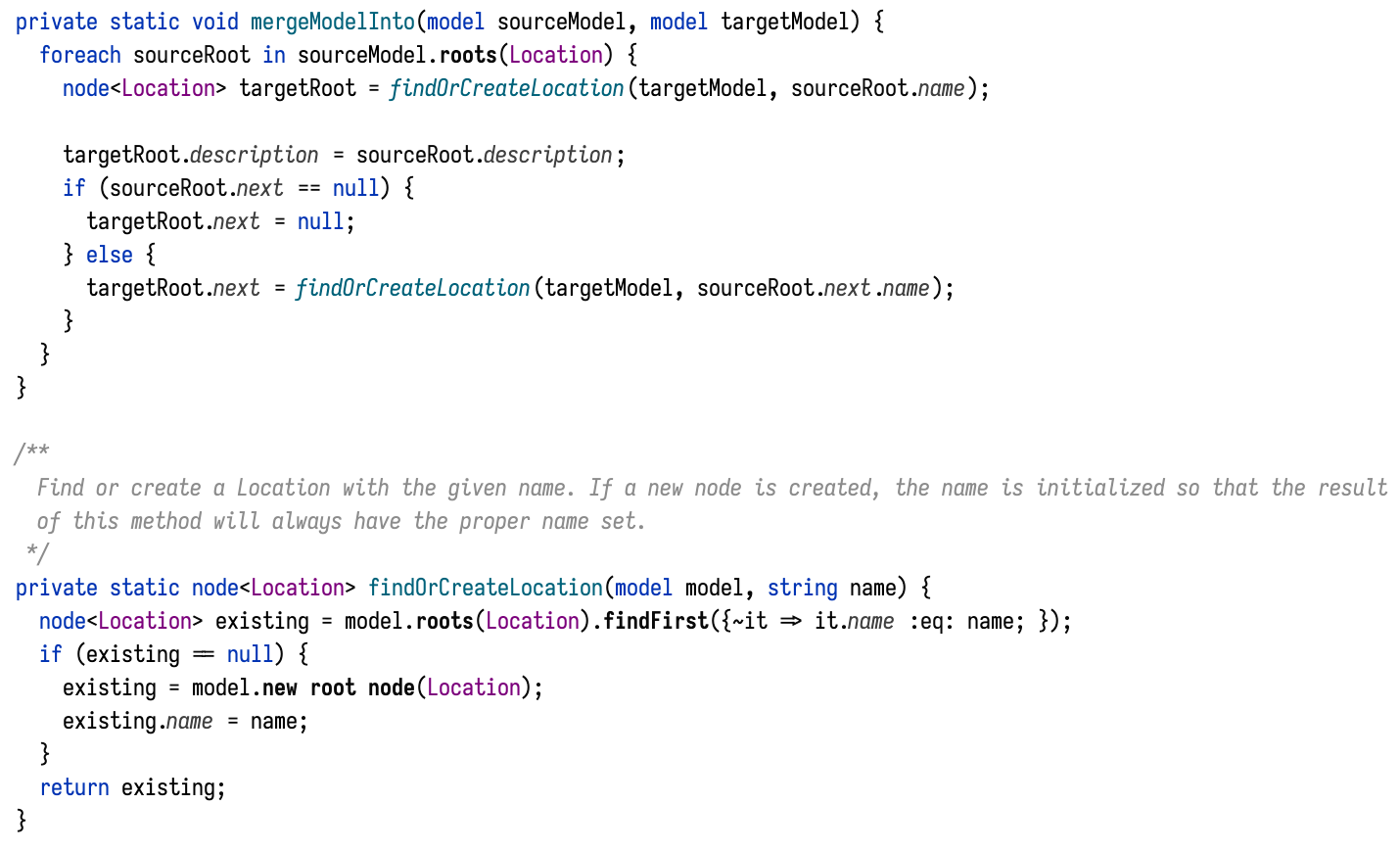
(The code can be found in the usual place on GitHub.)
This code can also be optimized by building a map of existing nodes rather than searching through the model each time. Otherwise, the simplistic approach works quite well. However, depending on your needs, you may need to modify your merge algorithm to provide answers to these questions:
-
What do we do with nodes that are present in the original model but not in the import? If these nodes are not supposed to be referenced from outside the model, it is safe to delete them. Another option could be to mark them as hidden or removed with a special boolean property. Or maybe even “commenting them out” using MPS universal comments.
-
Is the order of certain child nodes within their parent important? If so, the child list may have to be rearranged according to the incoming model.
-
What about forward references to child nodes, i.e. referring to a child node that does not exist yet. In this case you might not be able to add it to the model when you encounter it (like we do in
findOrCreateLocationin our example) because its parent may not exist yet. You could perhaps hold them in some kind of a “buffer” first, and at the end, check that the “buffer” nodes have all been added to the model (because they were visited from other nodes).
These considerations are shared among many importers, and Daniel Binkele-Raible from itemis has been working on a generic framework for merging models. It is currently undergoing review before it can be merged into MPS-extensions but you can see the current state in this pull request.